

All measurements of intelligence contain an amount of error - the average IQ test has a test-retest reliability of about .9, translating to a standard error of about 4.7 points. There are also indirect methods of estimating intelligence, such as standardized test scores, technical skill, wealth, gaming skill, and educational attainment. These measurements are less reliable than actual IQ tests, but sometimes they give enough signal to provide an accurate estimate of cognitive ability.
In order to estimate somebody’s intelligence with one measurement, the correlation that measurement has with IQ must be known (r), and the relative rank order the individual is on that measurement must be known as well (Mz). Then, the estimate of IQ can be calculated using the formula:
IQ = Mz*r*15 + 100 , where Mz is in z-score units.
For example, if the correlation between IQ and income is .35, and Jerry is 2 standard deviations above the mean in income, then Jerry’s estimated IQ is 110.5. Of interest is also the standard error of this measurement - based on my simulation, the standard error is 14 points. Therefore, the expected distribution in IQ of our Jerrys should look somewhat like this:
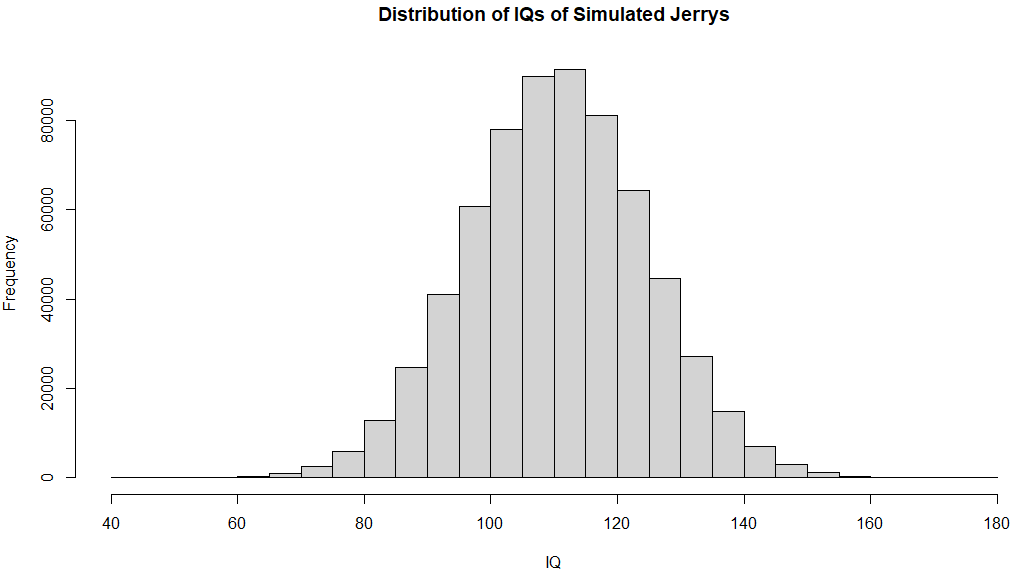
Unfortunately, it appears that income is not a very good predictor of intelligence - because of this, it is necessary to use multiple indicators or better ones.
There are several quantitative indicators of Elon Musk’s IQ:
He scored a 1400 on the old SAT, which translates roughly to 3 standard deviations above the mean. SAT scores and IQ correlate at roughly .84, so it’s a pretty good measurement of intelligence.
He is the most wealthy man in the world. While wealth and IQ barely correlate within normal people (r = .16), permanent income is more correlated with intelligence, and the wealth of extremely wealthy people is mostly a function of having a high permanent income. Because of this, highly intelligent people (e.g. Mark Zuckerberg, Elon Musk, Bill Gates) are overrepresented among billionaires beyond what would be expected based on the raw correlation. Currently, the correlation between permanent income and IQ is estimated to be roughly ~.37 (though unreleased research suggests it may be as high as .4-.5), though I use the figure of .35 globally for all measurements of income/permanent income/wealth for the purposes of consistency.
He reportedly achieved the highest score ever seen on a computer aptitude test. Unfortunately, in some cases like these, the exact rank relative to other people is not known, and must be conservatively estimated. I simply assumed that he scored the highest of at least 200 people, though realistically speaking this figure could vary from 100 to 10000. Estimations of the g-loading of technical ability is uncertain - in the ASVAB the electronics information subtest has a g-loading of about .74, while the auto/shop information test has a g-loading of about .65. These figures are somwhat inflated due to the fact that the tests themselves were used to calculate g, so I’ve stuck with a conservative estimate of the g-loading of technical/computational ability to be .6.
In order to estimate IQs using multiple traits, simulations can be used. This involves creating a distribution of IQs, then creating a distribution of other traits that correlate with intelligence, and then averaging the IQs of the individuals who conform to the particular traits that the person you are estimating has. For instance, if Jerry has a SAT score that is 1 SD above the mean and has a net worth that is 2SD above the mean, simulated distributions of those traits are made, and individuals who share those traits with Jerry have their IQs averaged.
Given that computational power is limited, the cutoff for wealth in this particular instance was relaxed - while Elon’s net worth is about 6 standard deviations above the mean, I included any individual who’s simulated wealth was 4 standard deviations above the mean due to the lack of computational resources.
Based purely on the figures I had used before (net worth at least 4 SD above the mean, SAT score between 2.9 and 3.1 SD above the mean, and technical ability 2.57 standard deviations above the mean), Elon Musk’s IQ is about 148 with a standard error of 7.6 based on the available indicators. This was the IQ histogram of the “simulated Elons”:

Even with real cognitive data and other metrics, the spread of potential true scores is rather wide.
I have been asked whether I think these kinds of estimates are valid, and my first response was this post. Overall, these are the issues I see with this method:
Most of the people are not randomly selected individuals - they are typically outliers in some field or space, and so they should regress to a mean that is not 100. Unfortuantely, it is difficult to define a reference distribution for them - as both the mean, the distribution, and the variance will be different, but there is no quantitative data to generate a reference distribution in this case. Because of this, regressing to the mean of 100 will cause the estimates to have a small downwards bias.
IQ cannot be conventionally measured above about 160 because a lot of very difficult questions are necessary to create a ceiling high enough, and many individuals are needed to norm tests at that ceiling accurately. Because of this, if somebody actually has an IQ of over 160, their IQ will probably be underestimated by a significant margin.
People tend to overreport their abilities, even numeric indicators like GPAs and SAT scores. Taking estimates at face value will cause a small upwards bias in scores.
While IQ has very linear relationships with most variables, it’s unknown as to whether severe outliers have increased regression to the mean. This doesn’t seem to be true for net worth, as there are three individuals with practically perfect SAT scores in the top 10, so I don’t think this is a major concern.
Some people have criticized my estimates for using only the most generous indicators of their performance. This will cause a small upwards bias in the aggregate estimates, but I don’t think it’s a relevant concern because most of these estimates use similar indicators (e.g. SAT, GRE, wealth, educational attainment, skill).
There is a non-zero amount of mathematical errors in these estimates. For some reason, when I initially calculated this estimate I divided Musk’s SAT score by 240 instead of 200, so his score was estimated to be 2.6 SD above the mean instead of 3.
Taking everything into account, I think that the correlation between “true IQs” and the estimates is about .7-.9, given that most of them use real cognitive data that is supplemented with real life indicators of success.
Code for elon estimate:
v <- c()
for(i in 1:100) {
set.seed(i)
g <- rnorm(60000000, mean=0)
iq <- 0.84*g + rnorm(60000000)*sqrt(1-0.84^2)
sc <- 0.35*g + rnorm(60000000)*sqrt(1-.35^2)
tk <- 0.6*g + rnorm(60000000)*sqrt(1-.6^2)
subby1 <- data.frame(iq, sc)
subby1$g = g
subby1$ed = ed
subby1$sc = sc
subby1$tk = tk
subby2 <- subset(subby1, (subby1$iq > 2.9) & (subby1$iq < 3.1) & (subby1$sc > 4) & (subby1$tk > 2.57))
v <- c(v, subby2$g)
}
mean(v)*15
sd(v)*15
Shouldn't Jerry's IQ be 110.5? I think you did it assuming SD is 10 for IQ