

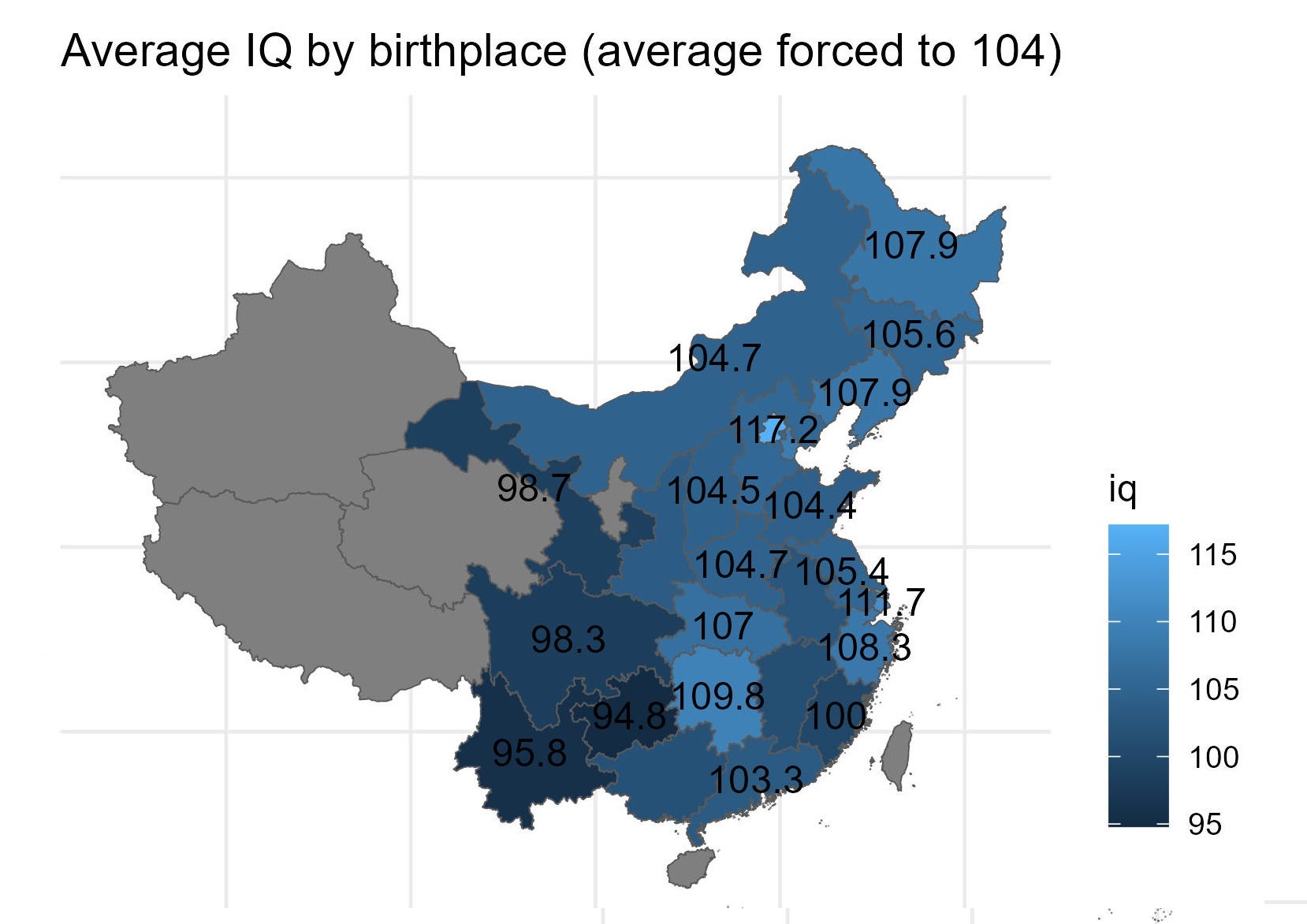
Update: these are the superior averages:
These differences use the better figure for the Chinese national IQ (100) and the averages from the Iodine study as well. Methodology etc is here.

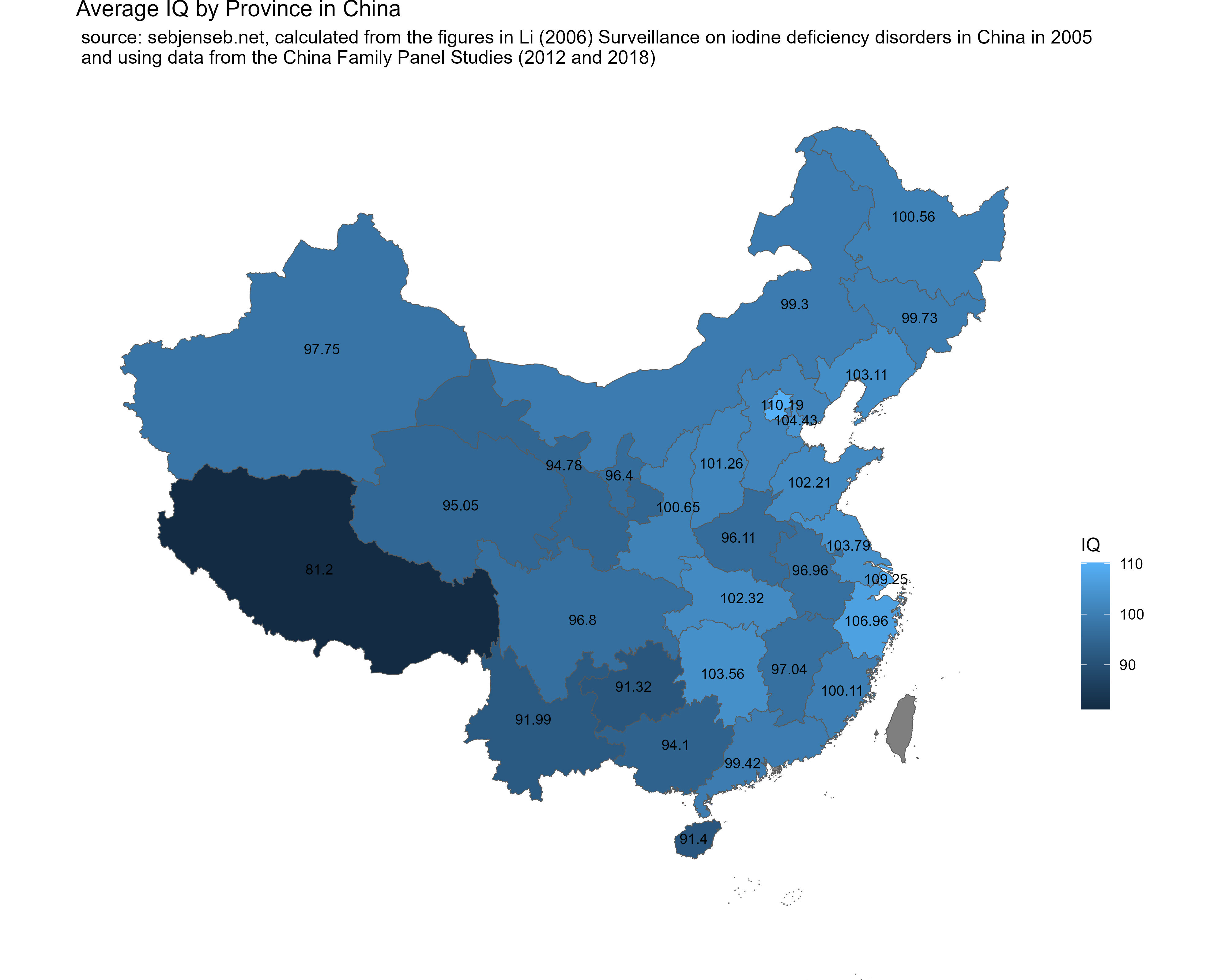
I recently tweeted out a map of the average IQ by Chinese province:

Given that some are skeptical of the Chinese government’s capability to collect this kind of research honestly, I decided to download the CFPS (Chinese NLSY) and tried to estimate the averages myself. I then calculated the average IQ by province and adjusted for selection bias detected within the study using the sampling weights. These were the results:
They correlate at .7 with the results from the iodine study, indicating that there is some consistency to both estimates.
Here’s a second one I made with added number series + memory data:

How much would the smaller urban numbers like the Beijing/Shanghai numbers be distorted by the fact that an official Chinese government study like the CFPS (run by the China Social Science Survey Center at Peking University) presumably only samples residents with hukous officially registered to the city, and omits the rest of the less elite population that actually live there?
Nice variable names